Data
👁🗨 Overview
There are two formats of the data, which are the images and bounding boxes data. The data format is as follows, each biopsy sample will be an image. Contestants will be given a set of pictures with the name sample_0001.bmp
🏷 Labels
The labels of the data are the bounding boxes (xmin, ymin, xmax, ymax). There could be more than one bounding box for each sample. For each bounding box, there will be a few associated classifications for the identified cells.
The classification is as follow:
| Class | SCC | AC | SCLC | NSCLC |
|---|---|---|---|---|
| English Name | Squamous Cell Carcinoma | Adenocarcinoma | Small Cell Lung Cancer | Non-Small Cell Lung Cancer |
| Index | 0 | 1 | 2 | 3 |
| Sub-class | NSCLC | NSCLC | ||
| Example Sample | 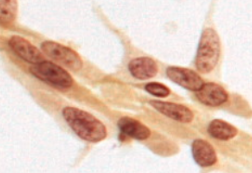 |
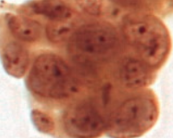 |
 |
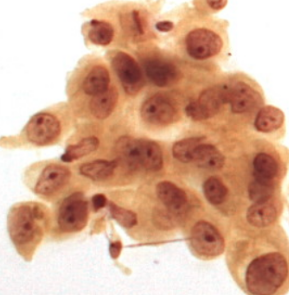 |
🏬 Datasets
There are a few subsets of datasets. The primary dataset for user training and validation is dataset_1. This dataset contains 1000 images.
| Dataset Name | Publicly Accessible | Description |
|---|---|---|
dataset_1 |
Yes | 1000 images for experimentation and model design. |
dataset_2 |
Restricted Access | User access through Huawei Cloud’s OBS, in ModelArts. |
1 Dataset Description - dataset_1
The data (
dataset_1) can be obtained through the OBS bucket from Huawei Cloud of the following URL.
https://msc21-dataset1.obs.cn-north-4.myhuaweicloud.com/dataset_1.zip
In the dataset_1 there are 1000 images, a CSV label file, and a metadata CSV file in zipped format. The file structure for the datasets (dataset_1) are as below:
- images
- sample_0000.bmp
- sample_0002.bmp
- …
- sample_0999.bmp
- labels.csv
- metadata.csv
A further description of the labels is in the Dataset Description Section.
2 Dataset Description - dataset_2
The data (
dataset_2) can be obtained through ModelArts Moxing Framework only. From Huawei Cloud's OBS Bucket
dataset obs path:
obs://msc21-dataset2/dataset
In the dataset_2 there are 3000 images, a CSV label file, and a metadata CSV file.
A further description of the labels is in the Dataset Description Section. Since you can only access the dataset through Moxing Framework in ModelArts, we highly encourage participants to use ModelArts for model training, because it is faster and more efficient for experimentation.
ModelArts Moxing Framework
Further information for ModelArts and Moxing is in the training and testing guidelines, this include the ways to import
dataset_2and how to handle files on the ModelArts.
🔢 Dataset Description
The images are in .bmp format, which can be easily read by common python packages.
The labels.csv contain few columns namely:
image_id, xmin, ymin, xmax, ymax, scc, ac, sclc, nsclc
The labels (xmin, ymin, xmax, ymax) will be floating-point numbers between 0 and 1. For the x-axis, the related columns are xmin and xmax, the value 0 corresponds to the left side of the image, and 1 corresponds to the right side of the image. For the y-axis, the same idea applies, but with 0 value at the top of the image and 1 at the bottom corner of the image.
The classes (scc, ac, sclc, nsclc) is the classification of the cancer cells because there are multiple classes per cell (multi-label classification problem), each class has a column with value 1 if the bounding boxes belong to the class. With the image_id the image filename can be obtained by concatenating the image_id with the .bmp file extension.
To facilitate some action in reading the dataset, we prepared the metadata.csv file, this file contains the metadata of the images with the columns namely:
image_id, width, height, bbox_count
This file is created to support participants in working with the dataset.
Be reminded that there are healthy samples in this dataset, which means images without any bounding boxes, these healthy samples will not have any column in the labels.csv, because they are healthy cells.
Image Count in datasets are as below:
| Dataset | Image Count |
|---|---|
dataset_1 |
1000 |
dataset_2 |
3000 |
The bounding box count distribution for each dataset are as below:
| Bounding Box Count | Percentage in dataset_1 |
Percentage in dataset_2 |
|---|---|---|
| 0 (Healthy Samples) | 32.40% | 33.30% |
| 1 | 28.70% | 27.93% |
| 2 | 16.50% | 17.87% |
| 3 | 12.10% | 9.43% |
| 4 | 5.20% | 5.10% |
| 5 | 1.90% | 2.70% |
| 6 | 1.00% | 1.73% |
| 7 | 0.50% | 0.77% |
| 8 | 0.30% | 0.27% |
| 9 | 0.30% | 0.33% |
| 10 | 0.11% | 0.57% |
The label's distribution of all bounding box for the datasets are as below:
| Dataset | SCC | AC | SCLC | NSCLC |
|---|---|---|---|---|
dataset_1 |
3.77% | 12.25% | 22.40% | 61.58% |
dataset_2 |
3.04% | 12.14% | 20.10% | 64.72% |
\* The distribution for the label NSCLC here does not include the subclasses AC and SCC
Contestants are expected to design a model for finding the bounding boxes for the samples and classify the diagnosed cells.
🔏 Dataset Terms and Conditions
- The data published by LBP Medicine does not contain patients’ information.
- The ownership and the copyright of the images and the labels belong to LBP Medicine.
- The use of the photos must abide by the Term of service of LBP Medicine.
- LBP Medicine guarantees that the data required in this competition are obtained through legal channels.
By participating in this competition, contestants are allowed to access this dataset. There is some limitation in the use of this dataset. The users shall only use this dataset within the competition. Within this competition, the definition of any code or software that accesses this dataset or reads this dataset in any manner must be part of the research or experimentation related to producing a model for this competition. The use of this dataset in the commercial context is prohibited.
The contestants accept full responsibility for the use of the dataset, including but not limited to the use of any copies of images that they may create from the dataset.
Commercial purposes include, but are not limited to:
- Training or proving the efficiency of commercial systems,
- Using screenshots of subjects from the dataset in advertisements,
- Selling a subset of data or the preprocessed forms of data from the dataset.
- Creating military applications.
The LBP Medicine reserves the right to modify and change this dataset and the section Dataset Terms and Conditions in this Rule Book and Guidelines for MindSpore Challenge - Pathology Diagnosis. This dataset comes without any warranty, and LBP Medicine cannot be held accountable for any damage (physical, financial, or otherwise) caused by the use of this dataset.